Bug dans les espaces de noms XML
Je sais pas si vous avez remarqué (intro faite et refaite, je sais) mais les espaces de noms en URI que vous avez en haut des pages html sont en http (pas 's'). Cela me posait question.
Sources :
- L’espace de noms en xml1.0
- L’espace de noms en xml1.1 et l’impossiblité de passer de http à https
- l’URN
Bug dans les espaces de noms XML
Les espaces de noms en URI que vous avez en haut des pages html sont en http (pas 's'). Cela me posait question.
Pour les spécialistes, xml est bien apparu après html. Effectivement, le terme “à l’origine” est mal choisi. Il notait la relation entre xml et html. Je n’allais pas entrer dans les détails des circonvolutions avec sgml, xhtml, etc…
Quelques notions
xml est un langage informatique qui est apparenté à html mais qui est utilisé dans de multiples autres documents (comme le pdf ou un fichier word). html c’est le langage qui permet de visualiser des pages web.
Si on regarde notre page d’accueil Limawi, en cliquant droit avec la souris et en visualisant le code source, on voit le html qui le compose.
Dans la première ligne de cet html, on voit ce qui ressemble à des liens. Ce sont des espaces de noms.

Pourquoi les espaces de nom XML sont-ils cassés ? OpenGraph
Pourquoi les espaces de nom XML sont-ils cassés ? OpenGraphEn xml, on peut décrire tout un tas de choses, comme ici un titre de page ou là une image avec ce qu’on appelle une balise.
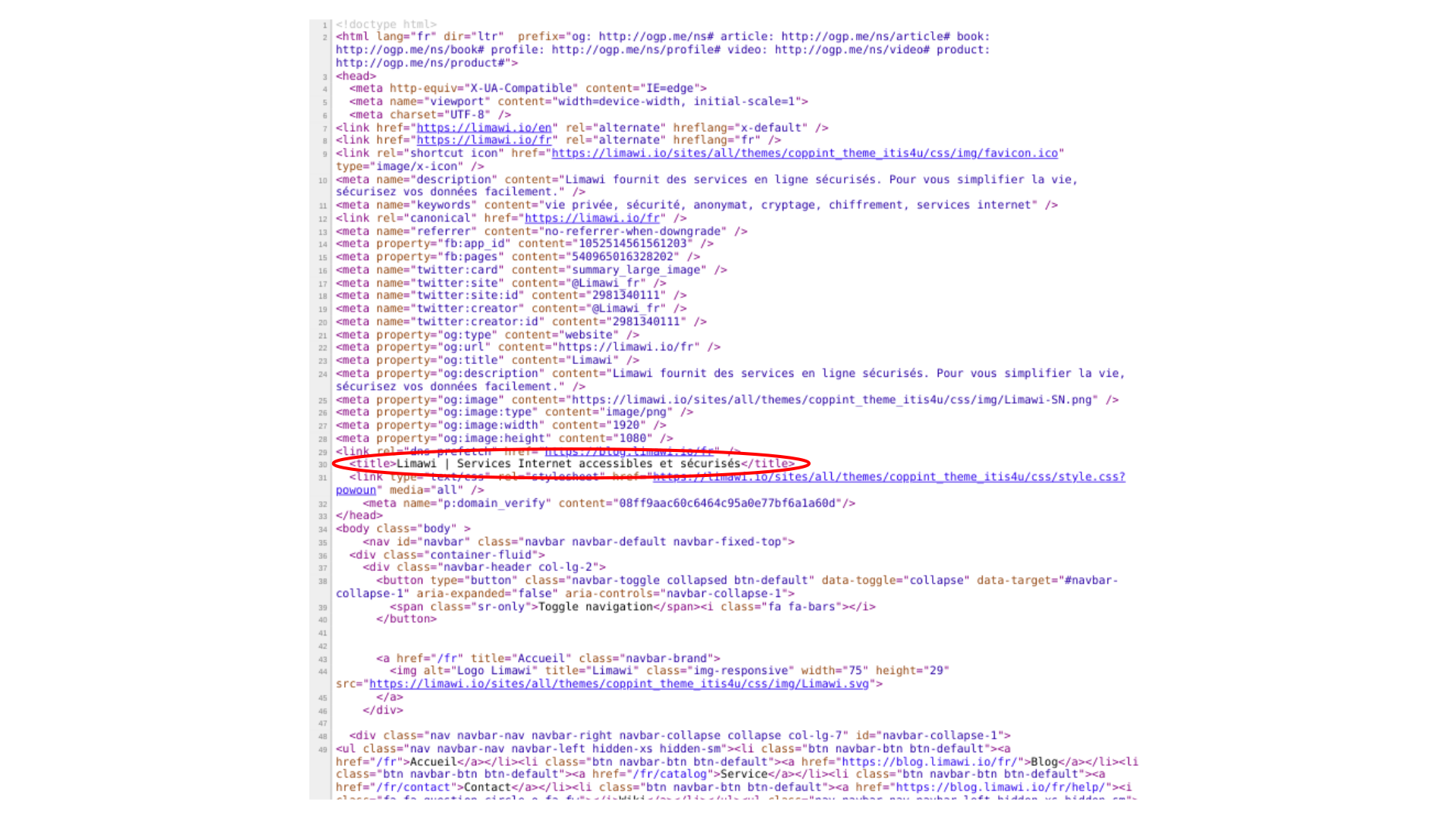
Balise titre en html
Balise titre en html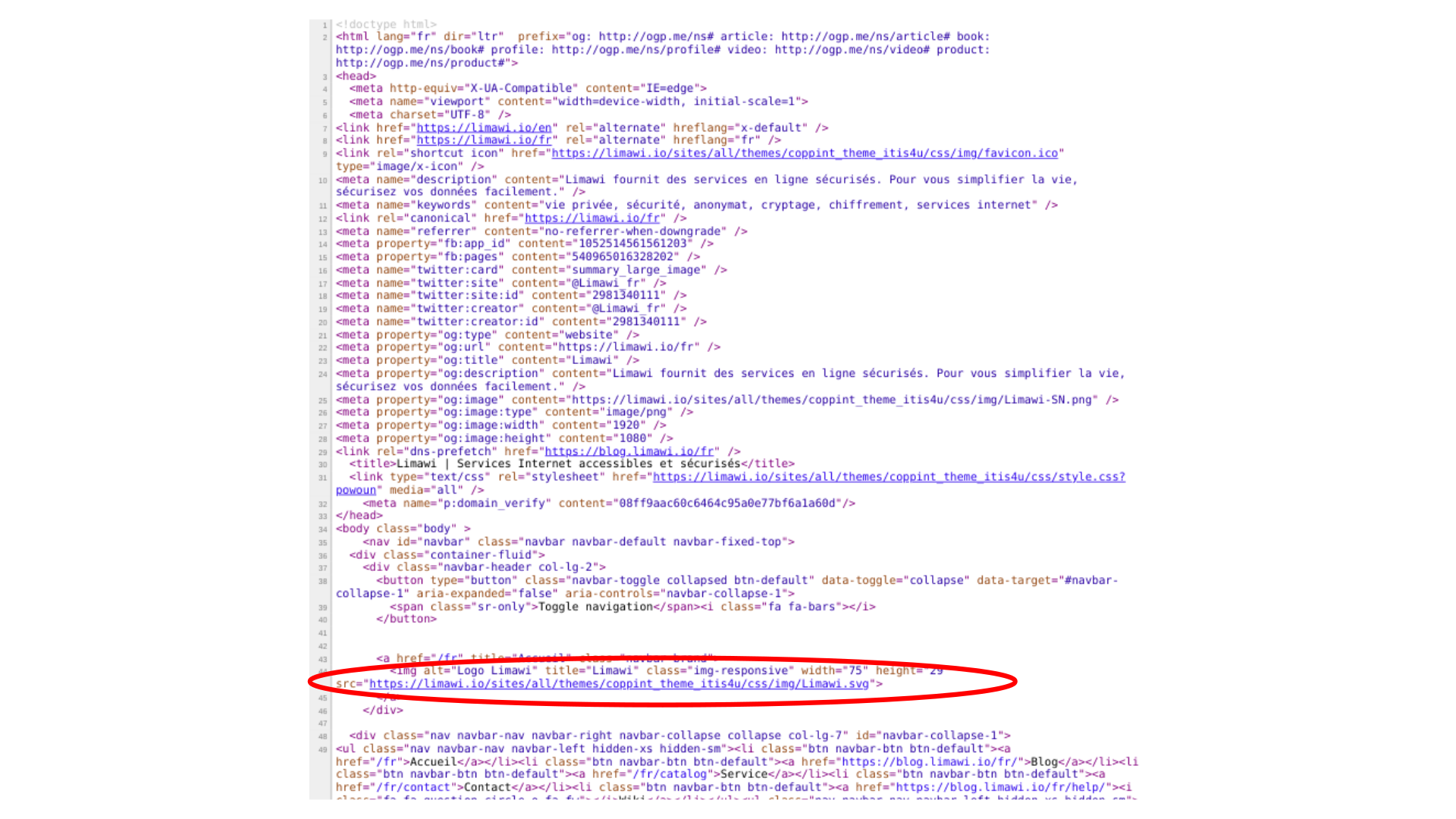
Balise image en html
Balise image en htmlPour que le navigateur comprenne que cette balise représente un titre, il lui faut une norme qui lui donne la définition de cette balise.
C’est à ça que servent les espaces de noms. Les liens que vous voyez tout en haut de la page définissent le fonctionnement de certaines balises qui y sont présentes.
Dans cet exemple, les liens que vous voyez définissent les balises qu’on nomme opengraph. Ce sont les balises qui enrichissent votre page dans Facebook, Twitter, et autres.
Avec le xml, on peut aussi mettre un autre document derrière ces liens, en xml lui aussi, qui définit les balises. Un document de définitions.
Ce language xml et ces dérivés comme le html, sont fixés par un organisme que l’on nomme le W3C pour World Wide Web Consortium.
Le problème
Le problème est que le W3C considère ces liens comme essentiellement des identifiants de définition.
C’est à dire que, quelle que soit la page, si on a cet espace de nom en haut de la page on sait qu’on aura les mêmes définitions.
Le W3C permet que ces liens ne mènent pas à un document de définitions et ne soient utilisés que comme identifiants. Le navigateur est sensé connaître déjà le document de définitions et ne suit donc pas le lien.
Ça soulève deux questions.
Question 1
La première, c’est que ça permet l’opacité des définitions. En effet, vous pouvez être poussé à utiliser un domaine de définition comme celui-là pour avoir de beaux liens sur Facebook, sans savoir exactement comment il fonctionne. Cela augmente artificiellement la quantité de travail de documentation et le risque d’erreur comme j’en ai déjà fait l’expérience.
J’ai voulu mettre en place la détection de pages traduites du blog Limawi en me servant de la documentation produite manuellement par les ingénieurs de Facebook. Voyant que ça ne fonctionne pas, j’ai contacté le support Facebook. On passe du temps. Au bout du bout, ils m’annoncent que cette fonctionnalité n’existe plus et qu’ils n’avaient simplement pas mis leur documentation à jour. Que de temps perdu stupidement.
Question 2
La deuxième question est bien plus importante. Ces liens, dans un comportement prévu par xml, peuvent être suivis pour aboutir au document de définitions. Le W3C n’interdit pas cette pratique et encore heureux car c’est une des beautés du xml et une des preuves du génie de Tim Berners-Lee.
By the way, Tim, big fan.
Mais en laissant ce flou sur les propriétés de ces liens, c’est à dire des identifiants de définitions qui peuvent aussi servir de lien vers le document de définitions, le W3C ouvre une faille de sécurité.
Beaucoup de ces liens sont en http. Comme le W3C est très strict sur la syntaxe d’un identifiant, on ne peut pas facilement les changer en https car c’est perçu comme un autre identifiant cassant le fonctionnement des systèmes qui s’y réfèrent.
On peut avoir un hacker qui intercepte le document de définitions dans le cas où un système va le chercher derrière le lien de l’espace de nom. Ce système n’a aucune possibilité de s’assurer que le document qu’il reçoit est le véritable document de définitions. Le hacker peut donc modifier le comportement du système.
À côté de cette façon d’identifier avec des liens, le W3C autorise aussi l’identification par un URN (uniform resource name) qui ne peut pas être confondu avec un lien. L’avantage de l’URN est qu’il n’y a pas d’ambiguïté, on sait que c’est purement un identifiant. Le navigateur doit trouver les définitions par un autre moyen.
D’où ma demande de faire évoluer la norme du W3C. Je comprends, même si je n’adhère pas, qu’on veuille garder pour soi ses définitions mais je voudrais garder le concept de lien vers le fichier de définitions. Ce concept est puissant, offre une flexibilité incroyable, la documentation est dans le code. C’est beau !
Mes propositions
Premièrement, on garde les liens mais ils doivent obligatoirement aboutir à un document de définitions et ne servent plus d’identifiants uniques. C’est le document de définitions qui a cette charge. On peut donc utiliser https au lieu de http et résoudre la faille.
Deuxièmement, on utilise l’URN comme identifiant pur pour les définitions que l’on veut garder opaques.
Ça ouvre des questions plus larges : « Qu’est ce qu’un bon identifiant ? qu’est ce qu’un mauvais identifiant ? ».